
Voici un sujet qui est particulièrement à la mode ici, au Québec, notamment l’utilisation de la méthode FAIR qui mérite une page dédiée. Je recommande d’ailleurs la lecture de l’ouvrage de jack Jones qui a créé la méthode pour quantifier le risque cyber (la nouvelle version de son livre est attendue en août 2024).
Les analystes de risque ayant un peu d’expérience n’ignoreront pas qu’il existe deux approches d’évaluation des risques : qualitative et quantitative. Les deux procèdent d’une même phase d’analyse du risque qui est la plus importante. Si les données en entrée de l’évaluation sont erronées ou non pertinentes, aucune approche ne pourra sauver l’évaluation : « garbage in, garbage out. »
La méthode qualitative utilise des valeurs ordinales (qui se mesurent les unes par rapport aux autres pour montrer une gradation) pour hiérarchiser les risques entre eux. Elle est relativement facile à modéliser et à utiliser et c’est la raison pour laquelle elle est largement utilisée. Surtout, la plupart des analyses de risques que nous faisons en TI et cyber n’ont aucune conséquence grave comme la perte d’une vie humaine, et nous n’envoyons aucune fusée sur la lune … ce n’est pas tant la précision qui est recherchée, mais une hiérarchisation des événements qui seront ordonnées entre eux, du moins grave au plus grave. Elle fait l’affaire pour gérer les priorités dans un programme. Le livrable le plus répandu pour présenter ces risques à la direction est la carte thermique de ces risques (heatmap) avec des zones de couleur représentant les degrés de gravité relative.
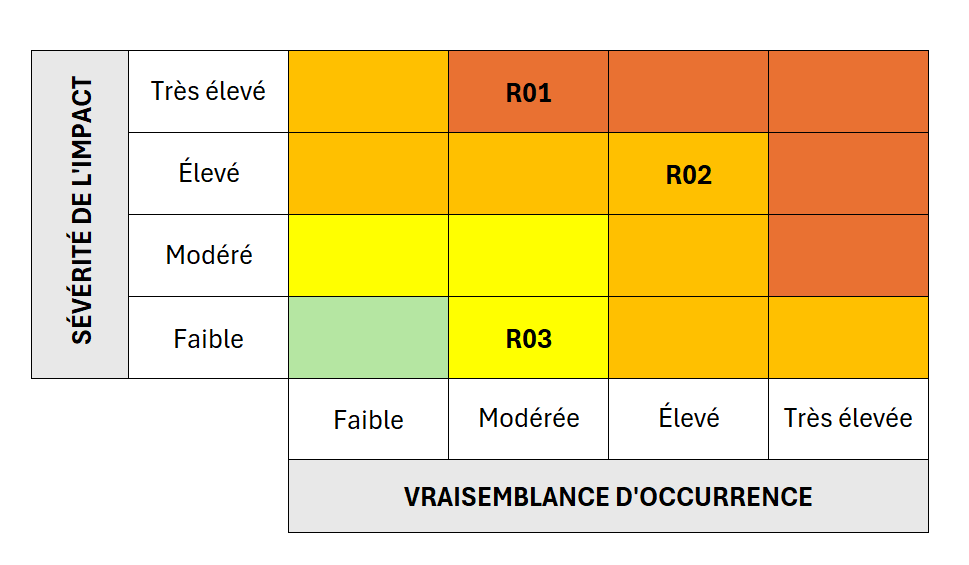
L’avantage de ce type de représentation est sa simplicité, sa compréhension est assez intuitive même pour des personnes qui ne sont pas dans le métier. Son inconvénient c’est que cela peut être simpliste et rigide, tout repose sur la qualité de l’analyse et de son argumentation pour soutenir la décision de placer un risque dans une zone ou dans une autre … et généralement la partie analyse est souvent très faible pour justifier ces choix qui semblent arbitraires.
Surtout, l’idée est juste de hiérarchiser et donc de donner une priorité d’investissement de chacun des risques. Le problème s’aggrave lorsque cette simplification dont la valeur est purement pédagogique donne lieu à des abus comme de placer des seuils d’acceptabilité des risques appelés parfois seuils de tolérance et d’autres, moins bien inspirés, seuils d’appétit au risque (ce qui mérite un autre article). C’est dangereux parce qu’ils règlent de manière excessivement rigide les risques dont on va s’occuper et ceux dont on ne s’occupera pas (ou moins vite). Or les risques sont toujours plus que les valeurs qui leur sont attribuées. Des risques de non-conformité réglementaire, même placés dans la zone modérée, méritent probablement une attention particulière (on dira que l’organisation a un appétit limité pour ce type de risques, surtout dans un secteur très réglementé comme le secteur financier). Il est aussi possible de pondérer davantage les impacts de certains types de risque, par exemple les risques de non-conformité seraient relativement plus élevés que des risques opérationnels.
L’autre problème avec cette approche réside dans le raccourci méthodologique qui consiste à multiplier (souvent) ou additionner (plus rarement) les valeurs estimées de vraisemblance et d’impact. Or, à moins de quantifier des risques, multiplier des valeurs ordinales n’a absolument aucun sens car elles ne représentent rien dans l’abslu sauf un degré relatif dans une échelle rigide allant de 4 à 10. C’est aller un peu vite dans l’interprétation de la formule (non mathématique) décriant un risque :

La véritable signification de cette formule, exploitant des propriétés arithmétiques basiques, c’est de dire que si un facteur est nul (on dirait sa valeur est égale à zéro), alors le risque est nul également. C’est une manière d’exprier simplement la nécessité de conjuguer les deux facteurs et non une formule magique permettant de qualifier des risques. Pour ma part, j’ai choisi depuis longtemps d’utililser la moyenne. Elle a pour avantage de ne jamais dépasser les valeurs extrêmes de base. Pr exemple si l’échelle est de 4 valeurs, de 1 à 4, la valeur moyenne ne sera jamais inférieure à 1 et ne sera jamais supérieure à 4. Par ailleurs, le calcul de la moyenne est une manière presque intuitive de conjuguer plusieurs facteurs. Si l’envie nous prenait de pondérer un facteur, il suffirait d’opter pour une moyenne pondérée. Mais en aucun cas on ne doit oublier qu’on ne calcule que la moyenne de valeurs ordinales, c’est-à-dire, représentant une hiérarchie, un ordre relatif et non une valeur absolue. En revanche, la multiplication prend tout son sens lorsqu’on souhaite quantifier des risques, car il n’y a pas une infinité de moyens pour conjuguer la probabilité d’un événement avec une perte financière …
Une carte thermique est un outil de discussion et de débat, sur la base des valeurs relatives et de leurs catégories (ou taxons). C’est, pourrait-on dire, un début plutôt qu’une fin en soi. C’est la raison pour laquelle on l’utilisera même pour des risques quantifiés, en remplaçant les valeurs ordinales par des fourchettes de valeurs. On retiendra alors sa portée pédagogique, plus que sa pertinence.
Revenons à la différence d’approches qui soulève toujours des débats houleux du même calibre qu’entre la science dure (mathématiques, physique) et la science molle (sciences sociales). Les défenseurs des évaluations quantitatives expriment des reproches très durs envers les évaluations qualitatives, excessives à mon sens, nourris d’idéologie et d’incompréhension. Les deux approches sont complémentaires, et cela aboutit souvent à une approche hybride ou semi-quantitative, surtout si on veut épargner aux différentes parties prenantes la douleur de se retrouver sur le banc de l’école pour apprendre ou réapprendre les probabilités.
Un risque est lié à un événement, souvent simpliste lui-même et à toute l’incertitude qui l’entoure. C’est un événement de menace ou événement redouté. Il fait peur et donc on veut pouvoir l’anticiper. Au début de l’analyse on connaît peu de chose sur lui, le plus souvent des idées préconçues nourries de lectures rapides de sources supposées autoritaires. L’objectif de l’analyse est donc d’étudier tous les aspects relatifs à cet événement afin de pouvoir évaluer les deux facteurs d’incertitude que sont son impact sur l’organisation et la vraisemblance de son occurrence. En effet, un événement a toujours une cause et une conséquence, cette dernière peut avoir un certain impact sur l’organisation. Pour en savoir plus au sujet de l’analyse, on pourra lire mon article dédié.
Si on veut qualifier un événement, on utilisera généralement une échelle de gradation explicite de type :
- Très élevé (ou Critique)
- Élevé
- Modéré
- Faible
La gradation a, idéalement un nombre de niveaux pair de sorte à éliminer le biais qui consiste à sélectionner la valeur moyenne par défaut. Je trouver personnellement que 4 niveaux est insuffisant pour avoir un minimum de granularité, mais il faut bien commencer quelque part. Imaginez-vous donner un niveau de risque agrégé pour l’ensemble de l’entreprise en 3 ou 4 niveaux. Est-il facile de faire comprendre à la haute direction la bonne utilisation des budgets, si d’année en année le niveau de risque est identique ? La réponse est évidemment non. Si on avait un ou deux niveaux additionnels, il serait plus facile de montrer une certaine progression, dans les sens où le niveau de risque diminuerait avec le temps et au fil de l’injection de dollars dans
Il reste qu’avec des niveaux qualifiés, des valeurs ordinales, des zones de couleur différentes, on peut facilement saisir visuellement le regard des lecteurs. Les gradations de couleurs thermiques du bleu/vert (pourquoi vert ?) au rouge sont suffisamment intuitives sans expertise en gestion des risques. Un drapeau de couleur comme sur les abords de la plage ou un sémaphore pourraient tout aussi bien faire l’affaire, tant que les niveaux suivent une logique simple saisissables par tous de manière uniforme.
La révolution de la quantification des risques ?
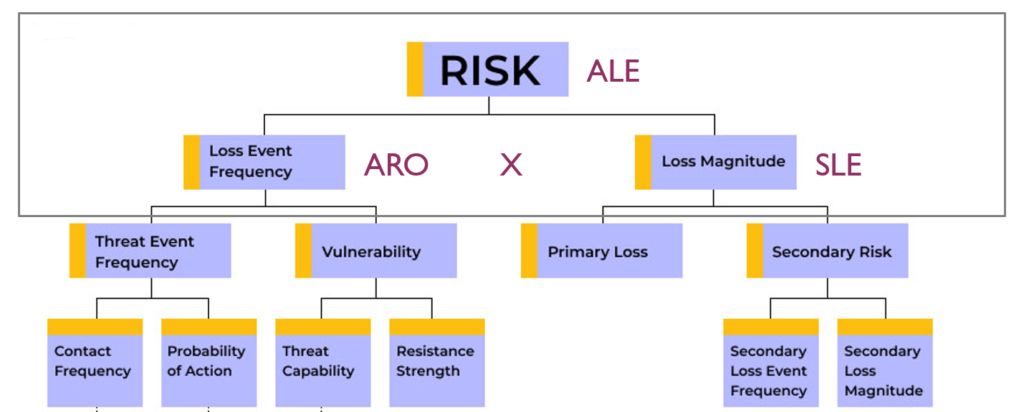
La question est rhétorique. Quantifier des risques n’est pas une révolution en soi, elle a toujours existé, juste pas dans tous les domaines. La manière la plus simple de quantifier les risques c’est d’utiliser la fameuse formule de Perte Annuelles Attendues (ou ALE, Annualized Loss Expectancy). Dans le sens de la quantification des risques, un risque est lié à un événement de perte. Donc une perte annualisée permet, en conjonction de la fréquence anticipée d’un événement de perte, d’évaluler un risque. Vous vous souvenez de la fameuse (non) formule pour qualifier un risque ? Voici donc sa version quantifiée :

C’est si basique, que même la méthode FAIR si en vogue de nos jours, est articulée autour de cette formule. Elle ne fait qu’ajouter avec plus ou moins de bonheur des éléments additionnels qu’on verra un peu plus loin.
Décomposons cette formule :
- ALE (Annualized Loss Expectancy, ou Perte Annuelles Attendues), c’est le coût du risque, la conjugaison des coûts engendrées par un événement de perte multiplié par la fréquence anticipée de ce type d’événement.
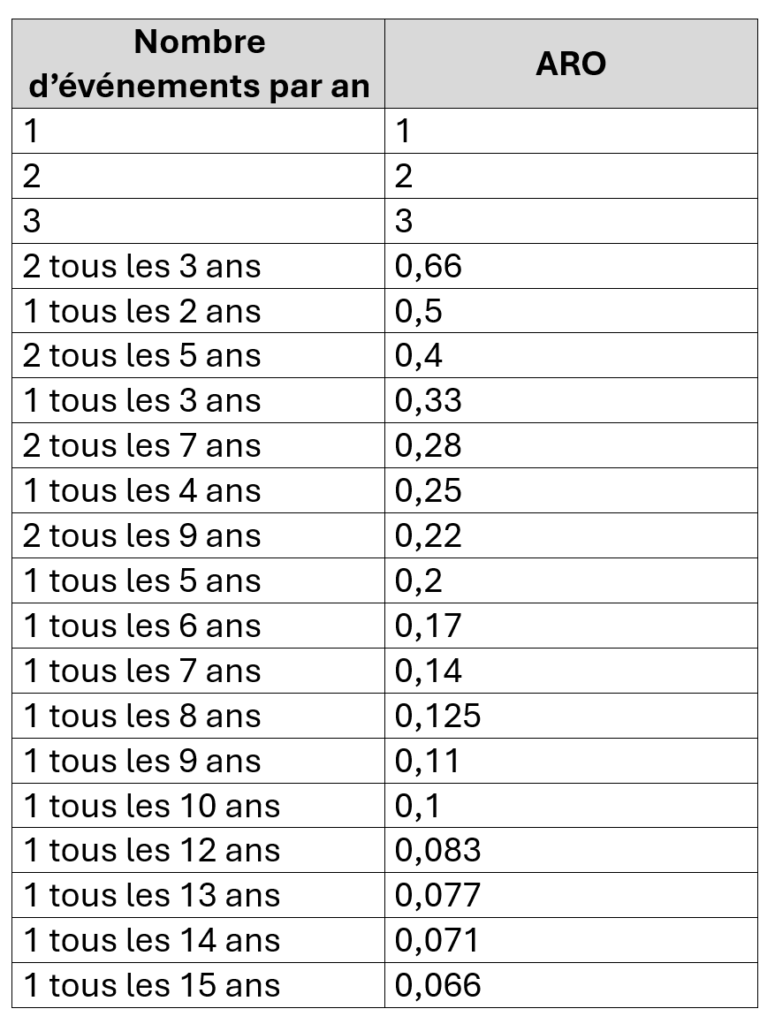
- ARO (Annual Rate of Occurrence, ou Taux d’Occurrence Annuel), c’est le nombre d’événements qu’on anticipe par an (p. ex. 0,5 c’est un événement tous les deux ans, 1 ce sera un seul événement, etc.)
- SLE (Single Loss Expectancy, ou Perte Unique Attendue), c’est le montant estimé pour un seul événement de perte, avant donc d’y appliquer le nombre d’événements attendus sur base annuelle.
Il reste à déterminer le coût d’un unique événement de perte. Selon la formule, on doit déterminer les éléments complémentaires par la formule SLE = EF x AV :
- EF (Exposure Factor, ou Facteur d’Exposition, c’est la quantité réelle de perte qu’on anticipe et dont l’utilisation est plus intuitive si elle est appliquée en cas de dommage physique d’un actif, dont c’était la portée initiale. UN événement de perte peut détruire une portion variable d’un actif, cette portion est exprimée en ratio ou en pourcentage : un bâtiment, un serveur peut être détruit à 10, 30, 80%.
- AV (Asset Value, ou Valeur de l’Actif) : c’est la valeur en dollars sonnant et trébuchants qu’on attribue à l’actif affecté par l’événement étudié.
Application de la formule simple de ALE dans le cas d’un bâtiment dont le coût est estimé à 800 000$ et dont on étudie le risque en cas de tremblement de terre. L’événement de perte étudié serait exprimé sous la frome d’un scénario de type : « Destruction (conséquence) de la salle de serveurs (actif) suite à un tremblement de terre (agent ET événement de menace) ».
- AV = 800 000$
- EF = destruction à 80%
- SLE = EF x AV = 800 000$ x 80% = 640 000$
- ARO = 0,083 (soit un événement tous les 12 ans, 1/12)
- ALE = ARO x SLE = 0,083 x 640 000$ = 53 333$ (annuels)
Si une organisation ne souhaitait pas atténuer ce risque inhérent, il lui faudra provisionner pour ces coûts. Dans le cas contraire, il lui faudrait trouver une solution pour réduire (ou atténuer) ce risque à hauteur de ce coût annuel.
Imaginons que le perte concerne un événement cyber, un serveur par exemple, le coût d’un événement de perte devra inclure l’ensemble des coûts induits par cet événement, soit : le coût annuel de licence logicielle de la solution de mitigation, le coût du support de cette solution, l’intervention en cas d’incident, etc. La Valeur de l’Actif reviendra potentiellement à évaluer le coût total d’un investissement ou coût total de possession (TCO, Total Cost of Ownership). Si on ne connaît pas la valeur de l’actif ou l’ensemble des pertes qui pourraient être engendrées en cas d’incident, ne pensez plus à quantifier le risque. Le résultat sera bien exprimé en dollars que comprendra la haute direction, mais clui-ci sera archi faux.
Dans le cas d’un événement cyber, la décomposition des pertes en utilisant le facteur d’exposition appliqué à la valeur aura moins de sens que pour un incident physique. Il y a deux alternatives, soit on ne considère que le coût estimé de l’incident, soit on applique le facteur d’exposition au processus sous-jacent.
Imaginons que l’actif affecté est un système de mission qui génère une partie non négligeable des ventes de l’organisation. Le facteur d’exposition pourrait être compris comme le pourcentage de ventes que le système sert à générer annuellement et donc les pertes potentielles directes.
toute la pertinence de la quantification des risques réside dans la capacité à obtenir des probabilités d’occurrence plausible des événements étudiés et de déterminer précisément les coûts engendrés par de tels événements.
Pour vous aider à trouver d’un coût d’oeil la valeur d’ARO qui s’appliquerait, voici un tableau de correspondances :
Pour voir les correspondances avec la taxonomie de la méthode FAIR :
Comment calculer la perte générée par un événement ?
FAIR distingue très justement les pertes directes (appelées primaires) des pertes indirectes (appelées secondaires), et souligne aussi que les pertes secondaires sont généralement plus élevées que les pertes primaires, mais qu’elles sont plus rares. Je précise qu’à mon avis, les pertes indirectes sont également plus difficiles à connaître avec exactitude, en dehors d’une divulgation de renseignements personnels fournissant des repères gravés dans la loi.
Sans aller trop dans le détail, voici la liste des catégories possibles de pertes qu’il faut prendre en compte durant une analyse quantitative :
- Pertes directes
- Destruction physique avec la diminution de la valeur de l’actif
- Indisponibilité (des données, du système support)
- Coûts de réaction aux incidents (ne pas tenir compte du salaire des analystes dont c’est le métier, mais plutôt des heures supplémentaires qui seront dues)
- Perte de revenu, de chiffre d’affaires
- Coûts engendrés par l’emploi de personnel supplémentaire, intérimaire
- Coûts de remplacement matériel ou logiciel
- Coûts de la perte de propriété intellectuelle
- Pertes indirectes
- Coûts relatifs à toute procédure judiciaire
- Coûts liés à la perte d’une licence pour les activités clé de l’entreprise (p. ex. licence bancaire)
- Coûts liés à l’intervention d’une autorité de régulation (p. ex. l’AMF)
- Coûts liés à la récupération de l’image de marque (p. ex. une agence de relations publiques)
- Coûts liés au remplacement d’un haut directeur démis de ses fonctions, emprisonné, etc.
Il est tout à fait possible, sinon souhaitable, d’associer une évaluation quantitative de certains risques à une évaluation qualitative qu’elle complétera avantageusement. Par exemple, on sélectionne certains risques qualifiés d’Élevés et Très élevés, et on les évalue financièrement pour donner un point de vue additionnel. On pourra challenger la qualification initiale et on vérifiera le niveau de perte associée afin de communiquer ces risques précis à la haute direction ou aux secteurs d’affaires pour les aider davantage à se situer. Je préconise d’ajouter cette évaluation non pas dans l’analyse de risque mais dans le registre des risques. Cette évaluation financière pourrait être la responsabilité de la deuxième ligne de défense (ou de la ligne 1B ou 1,5 lorsqu’elle existe).
Le calcul de l’ALE qui sert de base à la quantification des risques depuis les années 70 permet de déterminer le niveau de risque inhérent, c’est-à-dire sans prendre en considération les mesures de contrôle de ce risque. La partie de la quantification la plus délicate est celle justement liée à l’évaluation de l’efficacité de ces mesures et de trouver une manière de répercuter cela dans les résultats du risque inhérent, sans perdre en pertinence et en évitant de s’éloigner trop loin du rivage rassurant de la rationalité. S’il est relativement facile de quantifier un risque inhérent, il est infiniment plus difficile d’évaluer le risque résiduel. Je n’ai vu à ce jour aucune méthode ou outil facilitant cet exercice, je ne pense pas non plus qu’il y ait un consensus sur ce sujet (d’ailleurs aucun consensus n’est capable d’assurer un niveau de pertinence suffisant) mais j’essaierai dans un prochain article de proposer une approche qui me paraît logique à défaut d’être parfaite en tout point.
Igor S., CISSP, CRISC, ISO 27001